News
We open-sourced Bernini, a unified visual generation and editing model with performance on par with leading closed-source models.
A novel visual generation paradigm GRN is introduced.
We release a strong video generation model Waver that ranks Top3 in the Artificial Analysis Arena
Our text-to-image model Infinity based on VAR is available now with code and demo.
Our paper VAR wins the Best Paper Award in NeurIPS 2024.
We propose a new image generation paradigm VAR | Report.
15 papers are accepted in 2023y (PAMI 3, CVPR 4, ICCV 3 , ICLR 2, NeurIPS 1, and 2 papers in SIGIR and ACM MM)
Our ByteTrack ranks 1th of the most influential papers in ECCV 2022.
15 papers are accepted in 2022y (TIP 2, CVPR 3, ECCV 5 , NeurIPS 3, and 2 papers in ICLR and AAAI)
Our global team wins the first prize in the Trusted Media Challenge (TMC) combatting deepfakes [report]
Sparse R-CNN is accepted by CVPR 2021 and integrated by Detectron2, MMDetection and PaddlePaddle.
Our paper Controllable Orthogonalization is selected in Best Paper Award Candidates by CVPR 2020.
Selected Publications [Full List]
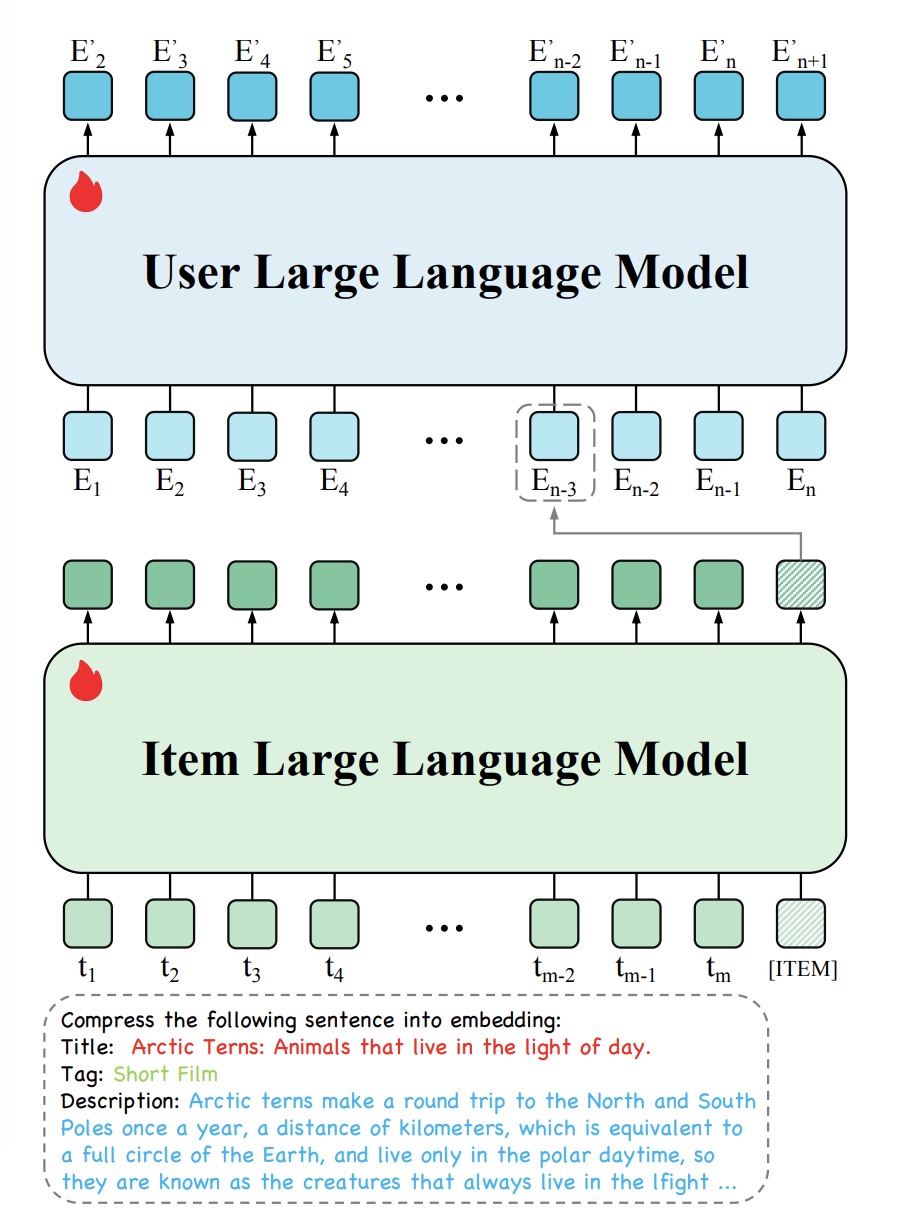
HLLM: Enhancing sequential recommendations via hierarchical large language models for item and user modeling
[arxiv paper]
[code]
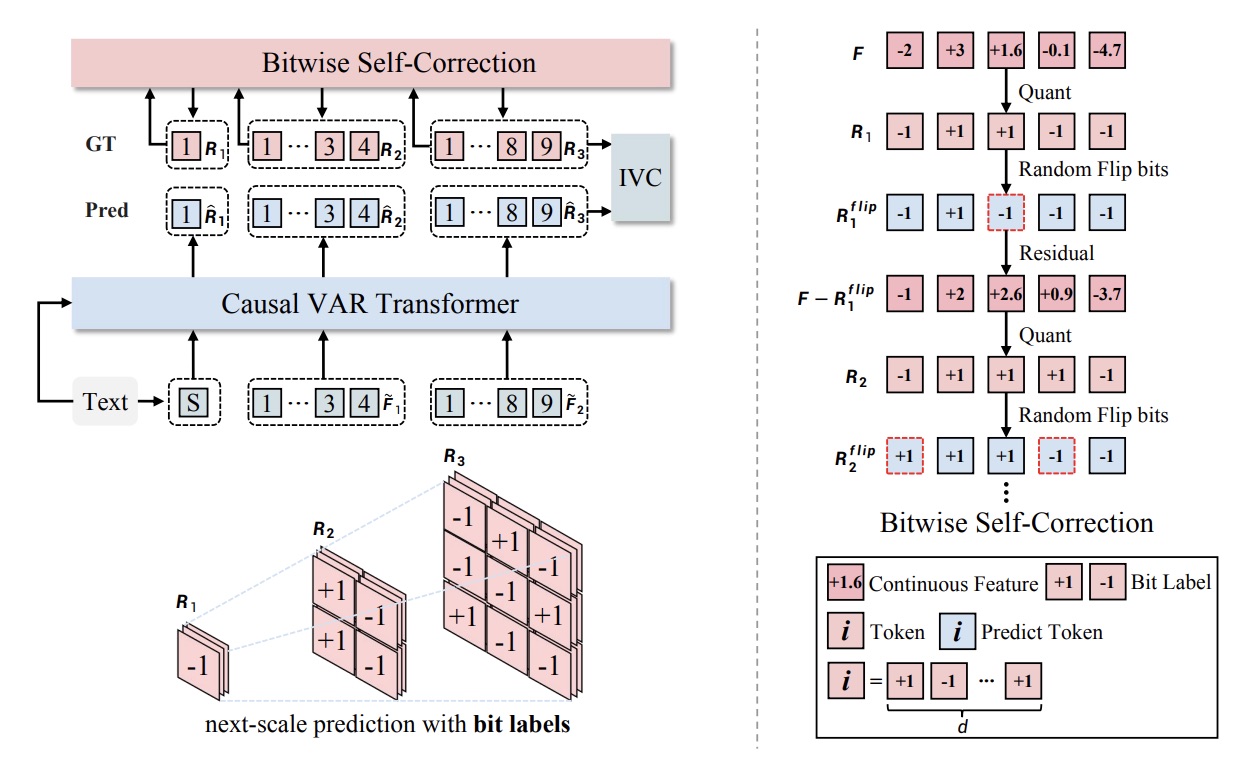
Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis
[paper]
[project]
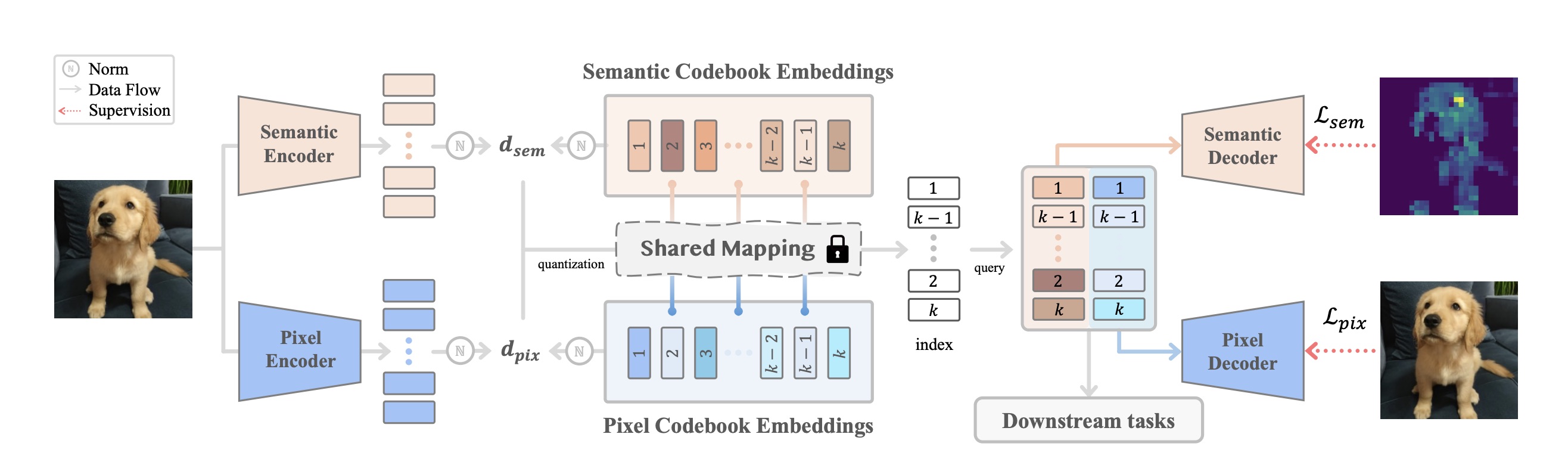
Tokenflow: Unified image tokenizer for multimodal understanding and generation
[paper]
[code]
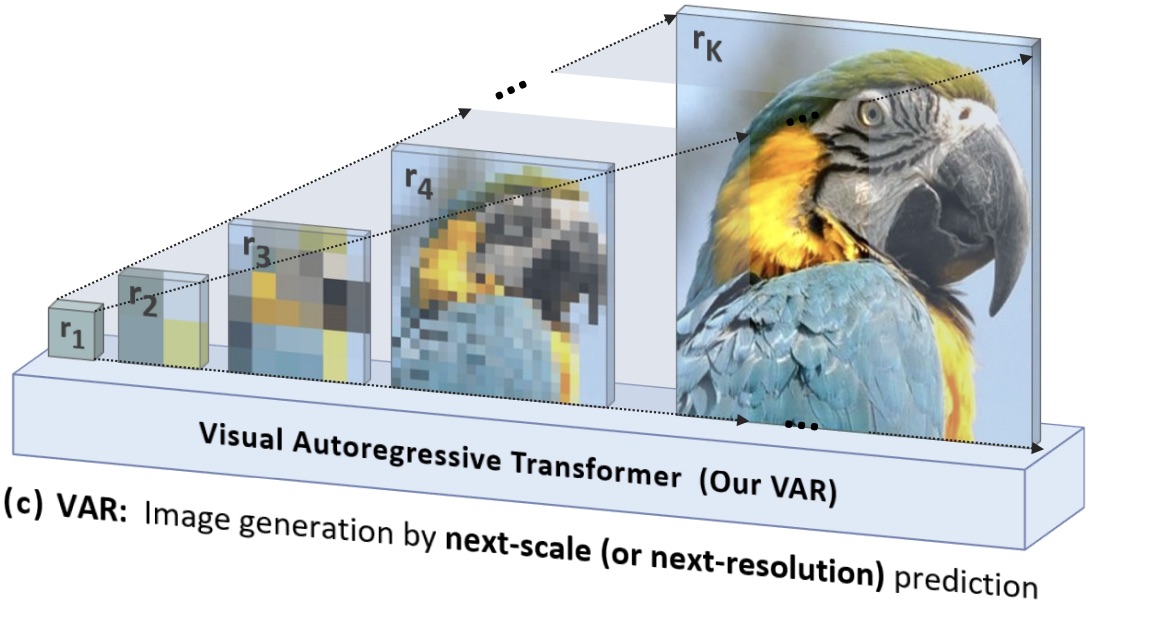
Visual autoregressive modeling: Scalable image generation via next-scale prediction
[paper]
[code]
Groma: Localized visual tokenization for grounding multimodal large language models
[paper]
[code]
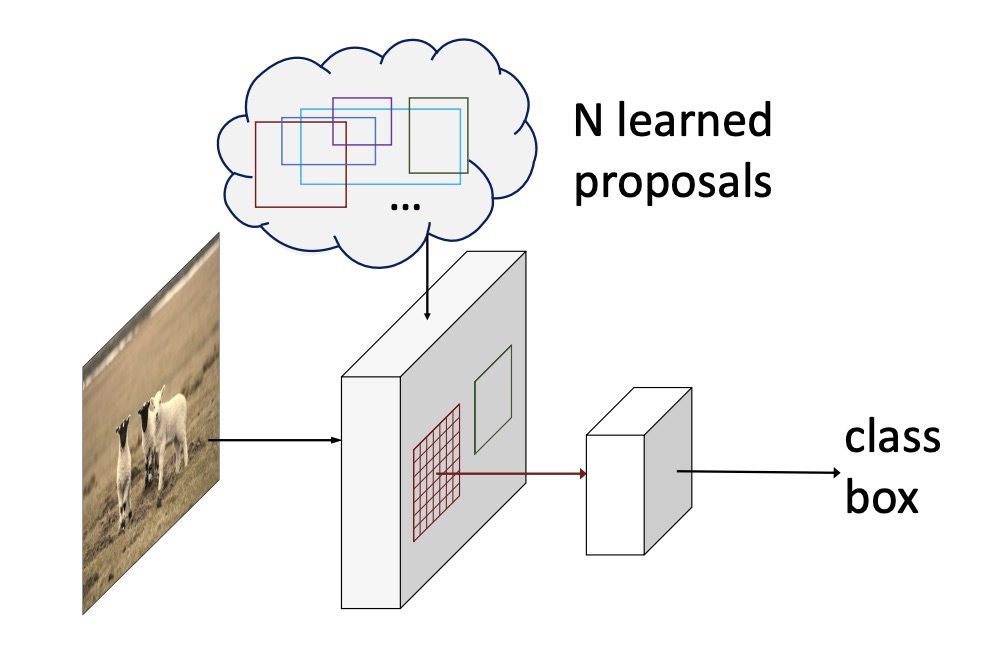
Sparse r-cnn: End-to-end object detection with learnable proposals
[paper]
[code]
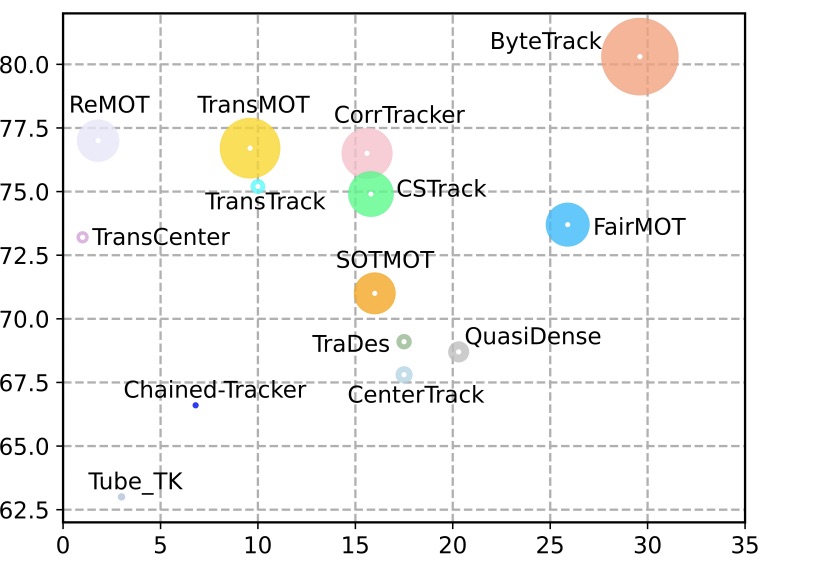
Bytetrack: Multi-object tracking by associating every detection box
[paper]
[code]